Storage¶
- Storage description
- Storage types
- Storage capacity
- Fault tolerance
- Volume description
- Available volume operations
Storage description
Data storage system
The storage system in the SIM-Cloud is built from software-defined storage (SDS). The best solution for SIMCloud tasks is a Ceph-based solution.
Ceph is a block and file access object storage area network (SAN) that is managed by free and open source software.
The Ceph distributed file system provides the following capabilities:
- replication (storage of spare duplicates of each data block in different network nodes);
- distribution of workload between nodes;
- creating duplicate data blocks (instead of unavailable ones) on other nodes, in the event of a disk, node or node group failure;
- rebalancing of data arrays when deleting (failure) nodes or adding new ones to the network (restoration);
- increase in performance due to caching (transfer of the most requested data and file system logs to the fastest disks).
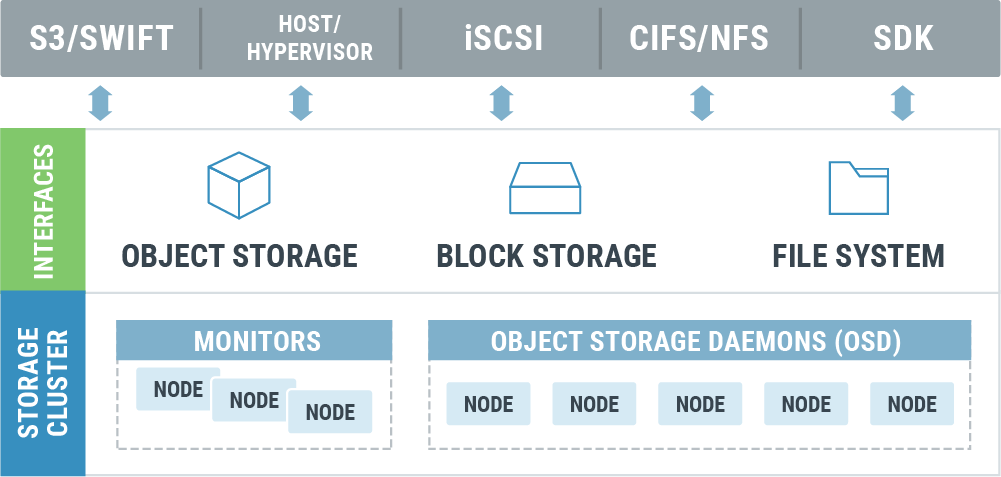
All this guarantees high availability and reliability of the data storage system.
Storage types
There are 2 storage types (cs1 and gs1) available in SIM-Cloud
- gs1 – general storage, universal storage; it is used for most services, it
- is also suitable for high-load applications with intensive data exchange.
cs1 – storage (cold storage), intended for low load tasks.
Storage capacity
For the convenience of comparing storages, we have placed their qualitative characteristics in a tabular form:
| Storage type | Bandwith | IOPS | Volume Size |
| cs1 | 200MB/s | 750/s | 1GB up to 2000GB |
| gs1 | 300MB/s | 10000/s | 1GB up to 2000GB |
- Carrying capacity - “Bandwidth”;
- The number of input-output operations - “IOPS”;
- Volume - “Volume Size”.
As can be seen from the table, gs1 storage has a higher throughput and significantly outperforms cs1 storage in terms of the number of I/O operations, which makes it sought after for heavily loaded systems with intensive data exchange.
Fault tolerance
All data in the SIM-Cloud storage system is replicated with a x2 factor (each identical data block is located on two different physical nodes placed in two different racks in the data centre).
Each project is assigned a specific quota for storage type cs1 or gs1. The amount of the required quota is determined by the owner of the project. Additionally, the user may increase the storage capacity.
Within the available quota of a particular storage type, a project user may create volumes, and create and launch instances on their basis.
Note
Please note that the documentation does not use the term “disk” as a physical device (hard disk), but instead use more precise definitions - “storage” or “volume” depending on the context. First of all, this is due to the fact that the main qualitative characteristics of a physical disk (bandwidth, IOPS) differ from the characteristics of a volume as understood by the openstack service. In addition, the terms “volume” or “storage” already implies the use of redundancy, due to which the fault tolerance and reliability of the block storage device is achieved.
Hereafter we will use only the terms “storage” or “volume”, and in exceptional cases, for better understanding, it is possible to use the term “disk”, please take note of this when reading our documentation.
Volume description
A volume is a block device based on cs1 or gs1 storage. Depending on the storage in which block devices are created, volumes inherit their performance metrics. This means that the volume created in the cs1 storage will have the following characteristics: bandwidth: 200MB/s, the number of IOPS is 750 IOPS, and the volume created in the gs1 storage will have the throughput: 300MB/s, the number of input-output operations is 10,000 IOPS.
One volume may be attached to only one instance at a time, while multiple volumes may be attached to the same instance. This means that you may mount multiple volumes and distribute your data between them to increase I/O resources and increase throughput. This is especially useful for database applications that often experience a large number of random read and write operations to a dataset.
The user may create both a boot (system) volume, from which the instance will be started in the future, or a “clean” volume - an empty volume that does not contain a file system or partition table. An “empty” volume may be attached to an instance as an additional volume.
Available volume operations
The project user has access to the following volume operations:
- Creating a volume
- Editing a volume
- Attaching a volume to an instance
- Disabling a volume
- Deleting a volume
- Extending a volume
- Changing a volume type
- Transferring a volume
- Taking a snapshot of a volume
- Deleting a snapshot
- Creating an image from a snapshot
You can learn more about the above volume operations in our article.